

A mesterséges intelligencia világában kevés technológia olyan lenyűgöző, mint az a képesség, amikor egy gép képes megérteni és feldolgozni az időbeli összefüggéseket. Minden nap használjuk azokat az alkalmazásokat, amelyek mögött ez a technológia dolgozik – a Google Fordítótól kezdve a Siri hangfelismerésén át egészen a Netflix ajánlórendszeréig.
A rekurens neurális hálózatok (RNN) pontosan ezt a varázslatos képességet biztosítják: lehetővé teszik a számítógépek számára, hogy "emlékezzenek" a korábbi információkra, és ezeket felhasználják a jövőbeli döntések meghozatalához. Ez olyan, mintha egy hagyományos neurális hálózatot felruháznánk memóriával és időérzékkel.
Ebben az útmutatóban mélyrehatóan megismerheted a rekurens neurális hálózatok működését, különböző típusait és gyakorlati alkalmazásait. Megtudhatod, hogyan különböznek a hagyományos feedforward hálózatoktól, milyen kihívásokkal küzdenek, és hogyan oldják meg a modern változatok ezeket a problémákat.
Mi az a rekurens neurális hálózat?
A rekurens neurális hálózat (Recurrent Neural Network, RNN) olyan mesterséges neurális hálózat, amely képes szekvenciális adatok feldolgozására azáltal, hogy belső memóriával rendelkezik, és a korábbi bemenetek információit felhasználja az aktuális kimenet generálásához.
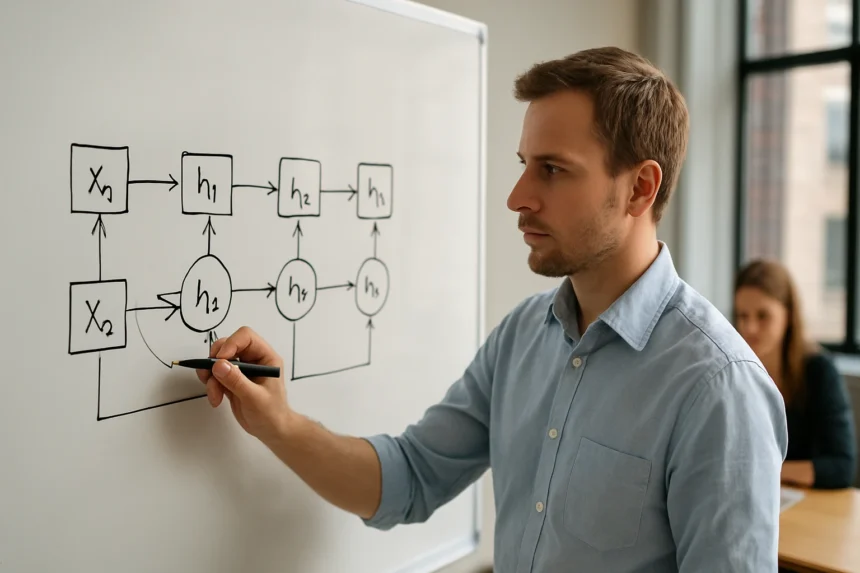
Az RNN-ek alapvető jellemzője, hogy ciklikus kapcsolatokat tartalmaznak, amelyek lehetővé teszik az információ áramlását nemcsak előre, hanem visszafelé is a hálózaton belül. Ez a tulajdonság teszi őket alkalmassá idősorok, természetes nyelvek és más szekvenciális adatok kezelésére.
A hagyományos feedforward neurális hálózatokkal ellentétben, ahol az információ csak egy irányban áramlik, az RNN-ek rejtett állapotokat (hidden states) tartanak fenn. Ezek az állapotok működnek a hálózat "memóriájaként", tárolva a korábbi időlépésekből származó információkat.
Hogyan működik egy RNN belső mechanizmusa?
Alapvető architektúra és információáramlás
Az RNN működésének megértéséhez képzeljük el a hálózatot időben "kiterítve". Minden időlépésnél (time step) a hálózat három fő komponenssel dolgozik:
- Bemenet (x_t): Az aktuális időpillanatban érkező adat
- Rejtett állapot (h_t): A hálózat belső memóriája
- Kimenet (y_t): Az aktuális időlépésben generált eredmény
A rejtett állapot frissítése minden időlépésben a következő képlet szerint történik:
h_t = tanh(W_hh * h_(t-1) + W_xh * x_t + b_h)
Súlymátrixok szerepe
Az RNN-ekben három fő súlymátrix található:
- W_xh: A bemeneteket a rejtett állapotba transzformálja
- W_hh: A korábbi rejtett állapotot kombinálja az aktuálissal
- W_hy: A rejtett állapotból kimenetet generál
Ezek a súlyok minden időlépésben ugyanazok maradnak, ami lehetővé teszi a paraméterek megosztását az egész szekvencia során.
Milyen típusai léteznek az RNN-eknek?
Vanilla RNN (Egyszerű RNN)
A legegyszerűbb RNN változat egyetlen rejtett réteggel rendelkezik, és tanh aktivációs függvényt használ. Bár koncepcionálisan egyszerű, gyakorlati alkalmazásokban gyakran küzd a gradiens eltűnése (vanishing gradient) problémájával.
Főbb jellemzői:
- Egyszerű architektúra
- Gyors tanítás
- Korlátozott memóriakapacitás
- Rövid távú függőségek kezelésére alkalmas
Long Short-Term Memory (LSTM)
Az LSTM hálózatok 1997-ben jelentek meg Sepp Hochreiter és Jürgen Schmidhuber munkájának köszönhetően. Ezek a hálózatok gate mechanizmusokat használnak az információ áramlásának szabályozására.
Az LSTM három fő gate-tel rendelkezik:
| Gate típus | Funkció | Aktivációs függvény |
|---|---|---|
| Forget Gate | Eldönti, mely információkat kell elfelejteni | Sigmoid |
| Input Gate | Meghatározza, mely új információkat kell tárolni | Sigmoid |
| Output Gate | Szabályozza, mit adjunk ki a cell állapotból | Sigmoid |
Gated Recurrent Unit (GRU)
A GRU az LSTM egyszerűsített változata, amelyet Kyunghyun Cho és csapata fejlesztett ki 2014-ben. Csak két gate-tel dolgozik:
- Reset gate: Meghatározza, mennyire felejtse el a korábbi rejtett állapotot
- Update gate: Szabályozza, mennyit frissítsen a rejtett állapotból
A GRU előnyei az LSTM-mel szemben:
- Kevesebb paraméter
- Gyorsabb tanítás
- Hasonló teljesítmény sok feladatban
Mik az RNN-ek fő alkalmazási területei?
Természetes nyelvfeldolgozás (NLP)
Az RNN-ek forradalmasították a nyelvtechnológiát. A Google Neural Machine Translation (GNMT) rendszere LSTM hálózatokat használ a fordításhoz, míg a sentiment analysis és szövegklasszifikáció területén is kiemelkedő eredményeket érnek el.
Konkrét alkalmazások:
- Gépi fordítás (Google Translate, DeepL)
- Chatbotok és virtuális asszisztensek
- Szövegösszefoglaló rendszerek
- Kérdés-válasz rendszerek
"A rekurens hálózatok képessége a kontextus megőrzésére tette lehetővé, hogy a gépek végre megértsék a nyelv árnyalatait és összefüggéseit."
Beszédfelismerés és hangfeldolgozás
A Deep Speech technológia és hasonló rendszerek RNN-eket használnak a hangjelek szöveggé alakítására. Az Amazon Alexa, Google Assistant és Apple Siri mind támaszkodnak ezekre a technológiákra.
Alkalmazási példák:
- Valós idejű beszédfelismerés
- Hangparancs feldolgozás
- Beszédszintézis
- Zene- és hangeffektus generálás
Idősor-előrejelzés
A pénzügyi szektorban az RNN-ek kiválóan alkalmasak részvényárfolyamok, devizaárfolyamok és egyéb pénzügyi mutatók előrejelzésére. A JPMorgan Chase és a Goldman Sachs is alkalmaz hasonló technológiákat.
"Az idősorok komplexitása és nemlinearitása miatt a hagyományos statisztikai módszerek gyakran elégtelenek, itt lépnek be az RNN-ek."
Hogyan tanítjuk az RNN hálózatokat?
Backpropagation Through Time (BPTT)
Az RNN-ek tanítása a Backpropagation Through Time algoritmussal történik. Ez lényegében a hagyományos backpropagation kiterjesztése időbeli dimenzióra.
A folyamat lépései:
- Forward pass: Végigfuttatjuk a szekvenciát
- Loss számítás: Minden időlépésben kiszámoljuk a hibát
- Backward pass: Visszafelé propagáljuk a gradienst
- Súlyfrissítés: Optimalizáljuk a paramétereket
Gradiens problémák és megoldások
Az RNN-ek tanítása során két fő problémával találkozhatunk:
Gradiens eltűnése (Vanishing Gradient):
- A gradiens exponenciálisan csökken a visszaterjesztés során
- Hosszú távú függőségek elvesznek
- Megoldás: LSTM, GRU, ResNet-szerű kapcsolatok
Gradiens robbanása (Exploding Gradient):
- A gradiens exponenciálisan nő
- Instabil tanítás
- Megoldás: gradient clipping, megfelelő inicializálás
"A gradiens problémák megoldása volt az a kulcs, amely lehetővé tette az RNN-ek gyakorlati alkalmazását komplex feladatokban."
Milyen kihívásokkal küzdenek az RNN-ek?
Számítási komplexitás
Az RNN-ek szekvenciális természete miatt nehezen párhuzamosíthatók, ami lassú tanítást és következtetést eredményez. A modern GPU-k párhuzamos feldolgozási képességeit nem tudják teljes mértékben kihasználni.
Teljesítményproblémák:
- Hosszú szekvenciák esetén lassú feldolgozás
- Memóriaigény lineárisan nő a szekvencia hosszával
- Nehéz skálázhatóság nagy adathalmazokra
Hosszú távú függőségek
Annak ellenére, hogy az LSTM és GRU hálózatok jelentősen javítottak a helyzeten, nagyon hosszú szekvenciák esetén még mindig problémás lehet a távoli információk megőrzése.
Hogyan viszonyulnak az RNN-ek más architektúrákhoz?
RNN vs. Transformer
A Transformer architektúra 2017-es megjelenése óta sok területen felváltotta az RNN-eket:
| Jellemző | RNN | Transformer |
|---|---|---|
| Párhuzamosíthatóság | Korlátozott | Kiváló |
| Hosszú távú függőségek | Nehézkes | Természetes |
| Tanítási sebesség | Lassú | Gyors |
| Memóriahasználat | Lineáris | Kvadratikus |
| Interpretálhatóság | Nehéz | Attention mechanizmus |
CNN-RNN hibrid megoldások
Sok alkalmazásban kombinálják a CNN és RNN előnyeit. Például képfeliratozásnál a CNN extraktálja a vizuális jellemzőket, míg az RNN generálja a szöveges leírást.
"A hibrid architektúrák lehetővé teszik, hogy kihasználjuk mindkét megközelítés erősségeit, miközben kompenzáljuk gyengeségeiket."
Mik a legújabb fejlesztések az RNN területén?
Attention mechanizmus integrálása
Az attention mechanizmus beépítése az RNN-ekbe jelentősen javította teljesítményüket. Ez lehetővé teszi, hogy a hálózat "odafigyeljen" a bemeneti szekvencia releváns részeire.
Előnyök:
- Jobb hosszú távú függőség kezelés
- Interpretálhatóbb modellek
- Javított teljesítmény fordítási feladatokban
Bidirectional RNN-ek
A kétirányú RNN-ek egyidejűleg dolgozzák fel a szekvenciát előre és hátrafelé is, így teljesebb kontextust kapnak minden időlépésben.
Alkalmazási területek:
- Szövegklasszifikáció
- Névelem-felismerés (Named Entity Recognition)
- Part-of-speech tagging
Hogyan implementálunk egy egyszerű RNN-t?
Keras/TensorFlow implementáció
A modern deep learning keretrendszerek egyszerűvé teszik az RNN implementációját:
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense
model = Sequential([
LSTM(50, return_sequences=True),
LSTM(50),
Dense(1, activation='sigmoid')
])
PyTorch megközelítés
A PyTorch rugalmasabb kontrollt biztosít az RNN implementáció felett:
import torch.nn as nn
class SimpleRNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(SimpleRNN, self).__init__()
self.rnn = nn.LSTM(input_size, hidden_size, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
"A modern keretrendszerek demokratizálták az RNN technológiát, lehetővé téve, hogy bárki könnyen kísérletezzen velük."
Milyen optimalizációs technikákat alkalmazhatunk?
Dropout és regularizáció
A dropout technika alkalmazása RNN-ekben speciális figyelmet igényel. A standard dropout a rejtett állapotok között alkalmazva káros lehet, ezért variational dropout-ot vagy recurrent dropout-ot használunk.
Regularizációs módszerek:
- L1/L2 regularizáció
- Batch normalization
- Layer normalization
- Gradient clipping
Tanítási stratégiák
Teacher forcing: Tanítás során a valós kimenetet használjuk bemenetként
Curriculum learning: Egyszerűbb példákkal kezdjük, majd fokozatosan nehezítjük
Scheduled sampling: Fokozatosan csökkentjük a teacher forcing használatát
Mik az RNN-ek jövőbeli kilátásai?
Specialized architektúrák
A kutatók specializált RNN változatokat fejlesztenek specifikus feladatokra:
- IndRNN: Független RNN neuronok jobb gradiens áramlásért
- SRU: Simple Recurrent Unit párhuzamos feldolgozáshoz
- QRNN: Quasi-Recurrent Neural Networks konvolúciós elemekkel
Edge computing alkalmazások
Az IoT eszközök és mobiltelefonok növekvő számítási kapacitása lehetővé teszi RNN-ek futtatását lokálisan, csökkentve a latenciát és növelve a privacy-t.
"Az RNN-ek jövője nem a teljes felváltásukban, hanem a specializált alkalmazásokban és a hibrid architektúrákban rejlik."
Gyakorlati tanácsok RNN projektek indításához
Adatelőkészítés
A megfelelő adatelőkészítés kritikus az RNN projektek sikeréhez:
- Szekvenciák normalizálása és padding
- Megfelelő batch méret választása
- Validation/test split időbeli sorrendben
Hyperparaméter tuning
Kulcsfontosságú paraméterek:
- Hidden size: A rejtett állapot dimenziója
- Number of layers: Rétegek száma (általában 1-3)
- Learning rate: Adaptív optimalizálók használata ajánlott
- Sequence length: Kompromisszum memória és teljesítmény között
Monitoring és debugging
Az RNN tanítás monitorozása speciális figyelmet igényel:
- Gradiens normák követése
- Hidden state aktivációk vizualizálása
- Attention weights elemzése
- Overfitting korai detektálása
Mik a rekurens neurális hálózatok fő típusai?
A három fő típus a Vanilla RNN (egyszerű), LSTM (Long Short-Term Memory) és GRU (Gated Recurrent Unit). Az LSTM és GRU speciális gate mechanizmusokkal rendelkeznek a hosszú távú függőségek jobb kezelésére.
Miért használunk RNN-eket a hagyományos neurális hálózatok helyett?
Az RNN-ek képesek szekvenciális adatok feldolgozására és memória fenntartására, míg a hagyományos feedforward hálózatok nem. Ez teszi őket alkalmassá idősorok, szövegek és beszéd feldolgozására.
Mi a gradiens eltűnése probléma az RNN-eknél?
A gradiens eltűnése azt jelenti, hogy a hibajel visszaterjesztése során a gradiens exponenciálisan csökken, így a hálózat nem tudja megtanulni a hosszú távú függőségeket. Az LSTM és GRU hálózatok ezt a problémát hivatottak megoldani.
Hogyan működik a Backpropagation Through Time (BPTT)?
A BPTT a hagyományos backpropagation kiterjesztése időbeli dimenzióra. A hálózatot időben "kiterítjük" és minden időlépésben számoljuk a hibát, majd visszafelé propagáljuk a gradienseket az összes időlépésen keresztül.
Mikor érdemes Transformer-t használni RNN helyett?
A Transformer-eket érdemes választani, ha párhuzamos feldolgozásra van szükség, hosszú szekvenciákkal dolgozunk, vagy amikor a tanítási sebesség kritikus. RNN-eket akkor használjunk, ha a memóriahasználat fontos, vagy valós idejű feldolgozásra van szükség.
Hogyan optimalizálhatjuk az RNN teljesítményét?
A teljesítmény javítható gradient clipping, dropout alkalmazásával, megfelelő inicializálással, batch normalization használatával, és a hyperparaméterek gondos hangolásával. A bidirectional RNN-ek is javíthatják az eredményeket.























